
Apache Flink主要应用在保证实时性的一些场景,比如(1)社交网站关注用户后,被关注者的粉丝数量立即变化;(2)疫情人数发生变化后防控级别的变化;(3)实时性ETL。
参考:Flink 应用场景
flink常见应用场景:
- 事件驱动型应用
事件驱动型应用是一类具有状态的应用,该应用会根据一个或多个事件流中到来的事件触发计算、更新状态或进行外部操作。事件驱动型应用常见于实时计算业务中,比如实时推荐、金融反欺诈、实时规则预警等。
事件驱动型应用将状态保存到本地,相比于传统数据库远程查询数据库,可以很大程度减少处理时间。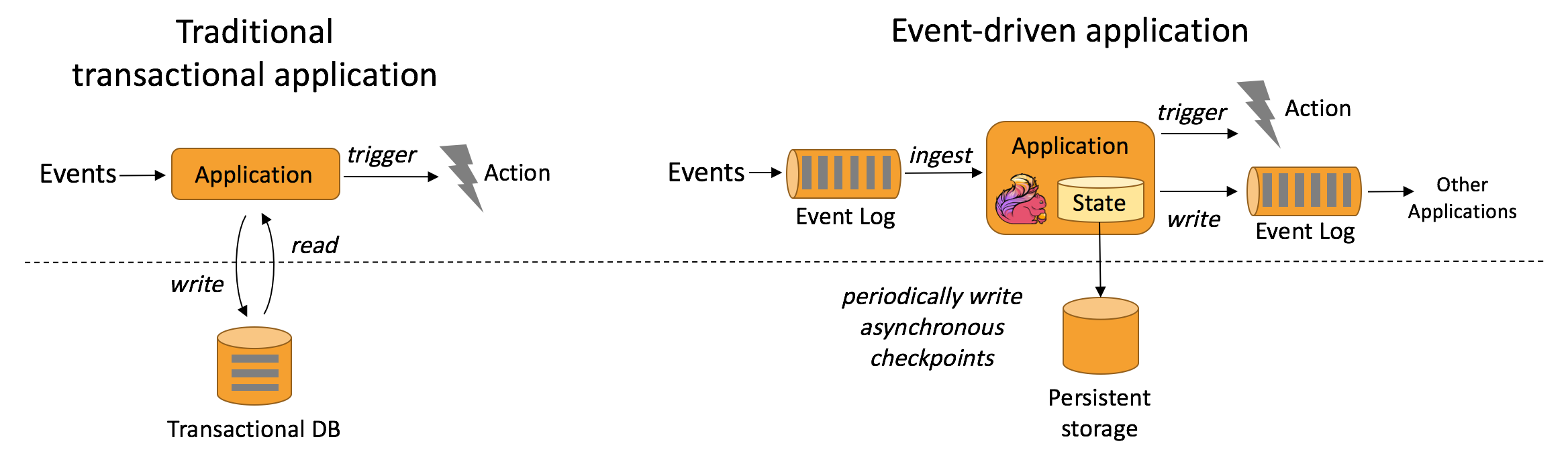
- 实时性数据分析应用
数据分析应用是指从原始数据中提取有价值的信息和指标,分为批处理分析和流处理分析。
批处理主要处理某个时间区间内的数据,当要分析最新时间的数据时,必须将新的数据再加入处理的数据集中才能进行分析。
流处理分析是实时性分析,其维护了从开始时间点至现在的所有数据,最新的数据到来时会产生新一轮分析,从而保证分析结果的实时性。比如实时分析疫情人数的变化确定防控级别。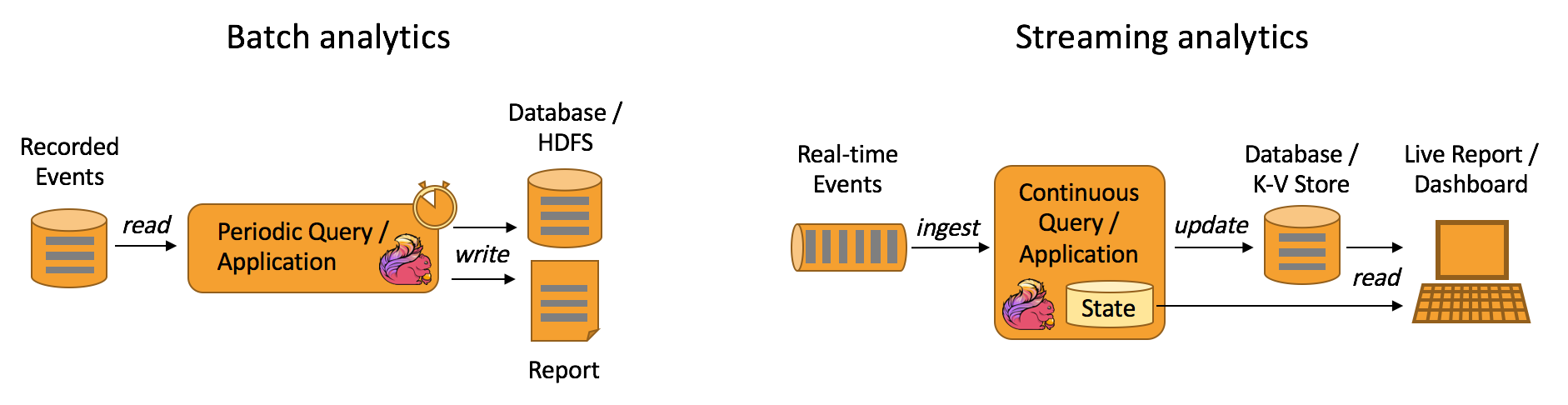
- 数据管道应用
数据管道型应用类似于ETL,可以看作是实时性ETL。ETL是提取(extract)、转换(transform)、加载(load)的是缩写,是一种在各存储系统之间进行数据转换和迁移的常用方法。ETL一般周期性地进行,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道可以持续性地从某个数据源端读取数据,并将他们转换加载到目的存储端。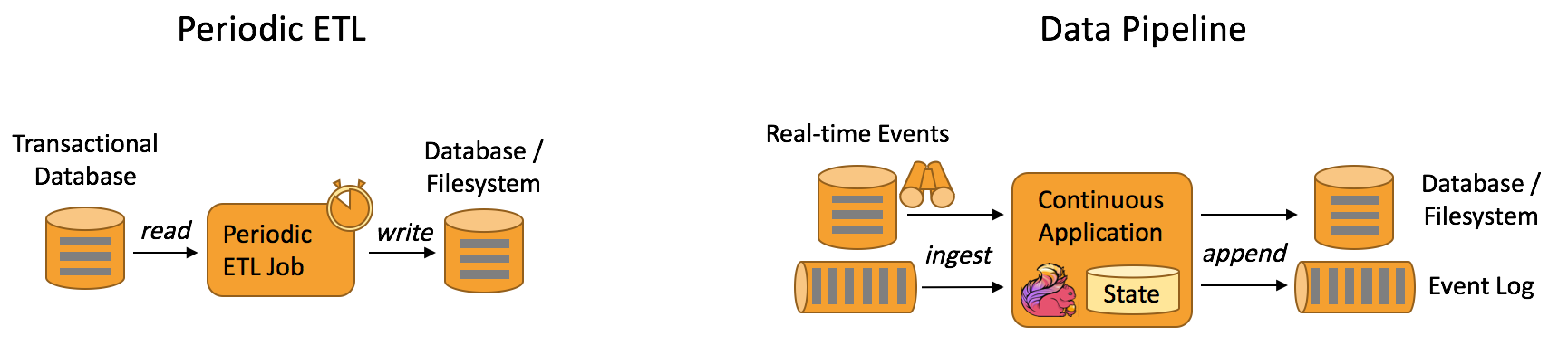
flink处理数据管道作业的优势:- 丰富的Connector连接数据源和目的端
- 强大的数据转换能力
- 内置多种聚合函数,具备强大的数据聚合能力
- 最重要的是”低处理延迟”

Q&A:
Q:为什么有ETL?
A: ETL的目的大多是为了解决信息孤岛的问题,举个例子,一个公司可能有客户数据、产品数据、销售数据等多个模块的数据,他们之间都是相互隔离的,任一单独的数据并不能发挥任何价值,ETL的存在,就是将这些数据聚集起来,然后就可以通过全局型的数据分析进行战略决策等。
Q:新概念ELT和数据湖是什么?
ELT:ELT的缩写同ETL,不同于ETL的数据提取、执行特定转换后加载到目的存储系统,ELT只是将数据提取后就加载到目的存储系统,然后交由目的存储系统做数据转换。ELT的优势在于目的存储系统可以根据不同应用的不同需求而选择不同的转换引擎对数据执行不同方式的处理。
由此可以引出的概念是”数据湖(data lake)”,广义的数据湖概念就是上面讲到的目的存储系统,既支持存储操作,也支持多种引擎的分析和转换操作。狭义的数据湖的概念是具备统一存储的系统。
参考:

